不均一系触媒上の反応解析(NEB法)¶
前節では有機分子を用いて、反応経路探索を行い活性化エネルギーを算出するNEB法の使い方を学びました。 本節では、より実用的な応用例として、不均一系触媒Rh上でのNO解離の反応解析を行ってみましょう。
流れとしては以下の目次のようになります。 触媒となるRh Slab部分の構造を作成し、その上に反応させたい対象となるNOを吸着させます。 その後、反応前後の状態を作成し、NEB法を用いて活性化エネルギーを算出します。
※本チュートリアルの内容はmatlantis-contribで公開されている計算事例を基にしています。
セットアップ¶
[1]:
import numpy as np
import pandas as pd
from IPython.display import display_png
from IPython.display import Image as ImageWidget
import ipywidgets as widgets
import matplotlib as mpl
import matplotlib.pyplot as plt
import os
import glob
from pathlib import Path
from PIL import Image, ImageDraw
import ase
from ase import Atoms, units
from ase.units import Bohr,Rydberg,kJ,kB,fs,Hartree,mol,kcal
from ase.io import read, write
from ase.build import surface, molecule, add_adsorbate
from ase.constraints import FixAtoms, FixedPlane, FixBondLength, ExpCellFilter
from ase.neb import NEB
from ase.vibrations import Vibrations
from ase.thermochemistry import IdealGasThermo
from ase.visualize import view
from ase.build.rotate import minimize_rotation_and_translation
from ase.optimize import BFGS, LBFGS, FIRE
from ase.md import MDLogger
from ase.io import read, write, Trajectory
from ase.build import sort
from pfp_api_client.pfp.calculators.ase_calculator import ASECalculator
from pfp_api_client.pfp.estimator import Estimator, EstimatorCalcMode
estimator = Estimator(calc_mode=EstimatorCalcMode.PBE_PLUS_D3, model_version="v8.0.0")
calculator = ASECalculator(estimator)
1. BulkからSlab作成¶
触媒として、今回はRhを用います。 Slab構造は、Bulk構造の構造ファイルから作成ができます。
1-1 Bulk構造を読み込みから作成まで¶
今回はMaterials Projectからダウンロードしたcifファイルをinputフォルダに入れて読み込み
[2]:
bulk = read("../input/Rh_mp-74_conventional_standard.cif")
print("Number of atoms =", len(bulk))
print("Initial lattice constant =", bulk.cell.cellpar())
bulk.calc = calculator
opt = LBFGS(ExpCellFilter(bulk))
opt.run()
print ("Optimized lattice constant =", bulk.cell.cellpar())
Number of atoms = 4
Initial lattice constant = [ 3.843898 3.843898 3.843898 90. 90. 90. ]
Step Time Energy fmax
LBFGS: 0 05:15:19 -25.543460 3.704290
LBFGS: 1 05:15:19 -24.790780 14.253086
/tmp/ipykernel_4043/294556526.py:7: FutureWarning: Import ExpCellFilter from ase.filters
opt = LBFGS(ExpCellFilter(bulk))
LBFGS: 2 05:15:19 -25.616249 0.694871
LBFGS: 3 05:15:19 -25.618728 0.134338
LBFGS: 4 05:15:19 -25.618814 0.001621
Optimized lattice constant = [ 3.79263361 3.79263357 3.79263381 89.99999254 89.99999872 90.0000003 ]
sort関数は、元素番号に応じて順序をソートする関数です。
[3]:
from pfcc_extras.visualize.view import view_ngl
bulk = bulk.repeat([2, 2, 2])
bulk = sort(bulk)
# Shift positions a bit to prevent surface to be cut at wrong place when `makesurface` is called
bulk.positions += [0.01, 0, 0]
view_ngl(bulk, representations=["ball+stick"])
[3]:
1-2 Slab構造を作成まで¶
bulk構造から任意のミラー指数でslab構造を作成。 miller_indices=(x,y,z)で指定できます。 makesurface は中で surface 関数を使用して表面構造を作成しています。
[4]:
from ase import Atoms
from ase.build import surface
def makesurface(
atoms: Atoms, miller_indices=(1, 1, 1), layers=4, rep=[4, 4, 1]
) -> Atoms:
s1 = surface(atoms, miller_indices, layers)
s1.center(vacuum=10.0, axis=2)
s1 = s1.repeat(rep)
s1.set_positions(s1.get_positions() - [0, 0, min(s1.get_positions()[:, 2])])
s1.pbc = True
return s1
[5]:
slab = makesurface(bulk, miller_indices=(1, 1, 1), layers=2, rep=[1, 1, 1])
slab = sort(slab)
# adjust `positions` before `wrap`
slab.positions += [1, 1, 0]
slab.wrap()
view_ngl(slab, representations=["ball+stick"])
[5]:
1-3 作成したslabのz座標を確認¶
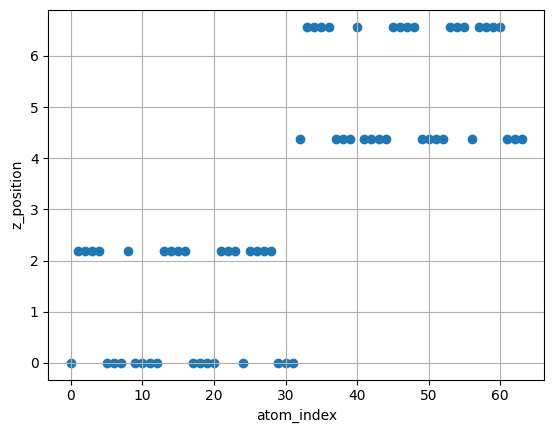
slabの最も高い座標確認(吸着構造を作成するときに必要) slabの層ごとの座標を確認(何層目までを固定するのか決めるのに必要)
[6]:
import plotly.express as px
# Check z_position of atoms
atoms = slab
df = pd.DataFrame({
"x": atoms.positions[:, 0],
"y": atoms.positions[:, 1],
"z": atoms.positions[:, 2],
"symbol": atoms.symbols,
})
display(df)
coord = "z"
df_sorted = df.sort_values(coord).reset_index().rename({"index": "atom_index"}, axis=1)
fig = px.scatter(df_sorted, x=df_sorted.index, y=coord, color="symbol", hover_data=["x", "y", "z", "atom_index"])
fig.show()
| x | y | z | symbol | |
|---|---|---|---|---|
| 0 | 1.007071 | 1.004082 | 9.621962e-09 | Rh |
| 1 | 10.393360 | 0.229914 | 2.189678e+00 | Rh |
| 2 | 2.347969 | 0.229914 | 2.189678e+00 | Rh |
| 3 | 1.007071 | 2.552418 | 2.189678e+00 | Rh |
| 4 | 6.370665 | 7.197427 | 2.189678e+00 | Rh |
| ... | ... | ... | ... | ... |
| 59 | 1.007071 | 5.649090 | 6.569035e+00 | Rh |
| 60 | 1.007071 | 1.004082 | 6.569035e+00 | Rh |
| 61 | -0.333827 | 6.423259 | 4.379356e+00 | Rh |
| 62 | 2.347970 | 6.423259 | 4.379356e+00 | Rh |
| 63 | 1.007071 | 8.745763 | 4.379356e+00 | Rh |
64 rows × 4 columns
[7]:
fig, ax = plt.subplots()
ax.scatter(df.index, df["z"])
ax.grid(True)
ax.set_xlabel("atom_index")
ax.set_ylabel("z_position")
plt.show(fig)
[8]:
print("highest position (z) =", df["z"].max())
highest position (z) = 6.569034565886692
1-4 表面切り出したslab構造の下層を固定して構造最適化¶
FixAtoms を用いることで、slab構造の下層の原子のみを固定してOptを実行できます。
ここでは1A以下を固定しており、一番下の層のみが固定されます。 表面の原子位置が緩和されるはずです。
[9]:
%%time
# Fix atoms under z=1A
c = FixAtoms(indices=[atom.index for atom in slab if atom.position[2] <= 1])
slab.set_constraint(c)
slab.calc = calculator
os.makedirs("output", exist_ok=True)
BFGS_opt = BFGS(slab, trajectory="output/slab_opt.traj")#, logfile=None)
BFGS_opt.run(fmax=0.005)
Step Time Energy fmax
BFGS: 0 05:15:26 -373.914913 0.174282
BFGS: 1 05:15:26 -373.928423 0.165866
BFGS: 2 05:15:26 -373.978414 0.136160
BFGS: 3 05:15:26 -373.984841 0.144724
BFGS: 4 05:15:27 -374.023178 0.114875
BFGS: 5 05:15:27 -374.032386 0.109831
BFGS: 6 05:15:27 -374.042219 0.101376
BFGS: 7 05:15:27 -374.047082 0.058459
BFGS: 8 05:15:27 -374.048953 0.014485
BFGS: 9 05:15:27 -374.049053 0.002408
CPU times: user 91.9 ms, sys: 11.6 ms, total: 103 ms
Wall time: 1.04 s
[9]:
True
実際のOptの経過を見てみると、上3層のみの構造最適化がされている事がわかります。
[10]:
view_ngl(Trajectory("output/slab_opt.traj"), representations=["ball+stick"])
[10]:
[11]:
slabE = slab.get_potential_energy()
print(f"slab E = {slabE} eV")
slab E = -374.0490526773523 eV
[12]:
# Save slab structure
os.makedirs("output/structures/", exist_ok=True)
write("output/structures/Slab_Rh_111.xyz", slab)
2. MoleculeをSlab上に配置、始状態(反応前)と終状態(反応後)を作成¶
2-1 吸着する分子読み込み、構造最適化後のpotential energyを得ましょう。¶
今回はaseのmolecule moduleを使います。 cif file, sdf fileなどからの読み込みもbulk構造を読み込みと同じように実施すればできます。
[13]:
molec = molecule("NO")
# example to read sdf file
# molec = read("xxxxxx.sdf")
[14]:
molec.calc = calculator
BFGS_opt = BFGS(molec, trajectory="output/molec_opt.traj", logfile=None)
BFGS_opt.run(fmax=0.005)
molecE = molec.get_potential_energy()
print(f"molecE = {molecE} eV")
molecE = -7.206895204744375 eV
[15]:
view_ngl(Trajectory("output/molec_opt.traj"), representations=["ball+stick"])
[15]:
2-2 吸着E計算¶
吸着状態を作成しましょう。 ここでは、add_adsorbate関数を用いてslab 上部に molec を配置しています。
[16]:
mol_on_slab = slab.copy()
# height: height of molecule from slab surface
# position: x,y position of molecule
# The molecule position can be modified later, and thus rough value is ok here.
add_adsorbate(mol_on_slab, molec, height=3, position=(8, 4))
c = FixAtoms(indices=[atom.index for atom in mol_on_slab if atom.position[2] <= 1])
mol_on_slab.set_constraint(c)
SurfaceEditor¶
SurfaceEditorというクラスを用いて分子の吸着位置最適化を行います。
SurfaceEditor(atoms).display()で編集したい構造を表示しましょう。atoms z>で動かしたい分子のindexを取得しましょう。1-3で確認したslab構造の最も高い座標より上にいるのが分子です。設定すると下のボックスに選択された分子のindexのみが入ります。
move, rotateのXYZ+-で分子のみを移動、角度変更できますので、位置を調整してください。この際、Ball sizeを調整すると吸着サイトが見やすくなります。
“Run mini opt” ボタンで、BFGSによる構造最適化を指定ステップ実施できます。
今回は以下の論文を参考に吸着構造を作成してみます。
”First-Principles Microkinetic Analysis of NO + CO Reactions on Rh(111) Surface toward Understanding NOx Reduction Pathways”
今回の例では、“X-”を3回、“Y+”を1回、“Z-”を4回押すことでHCPサイトの吸着を行うための初期構造を作ることができます。 吸着のFCCサイト、HCPサイトに関しては以下の図をご覧ください。
(Colour) Possible adsorption sites (top, bridge, hollow-hcp and hollow-fcc) for hydrogen (dark red) on the Mg(0001) surface (light blue). from https://www.researchgate.net/figure/Colour-Possible-adsorption-sites-top-bridge-hollow-hcp-and-hollow-fcc-for-hydrogen_fig1_5521348

[17]:
# calculator must be set when SurfaceEditor is used
mol_on_slab.calc = calculator
[18]:
from pfcc_extras.visualize.surface_editor import SurfaceEditor
se = SurfaceEditor(mol_on_slab)
se.display()
[19]:
c = FixAtoms(indices=[atom.index for atom in mol_on_slab if atom.position[2] <= 1])
mol_on_slab.set_constraint(c)
BFGS_opt = BFGS(mol_on_slab, logfile=None)
BFGS_opt.run(fmax=0.005)
mol_on_slabE = mol_on_slab.get_potential_energy()
print(f"mol_on_slabE = {mol_on_slabE} eV")
mol_on_slabE = -383.5784582025796 eV
[20]:
os.makedirs("output/ad_structures/", exist_ok=True)
write("output/ad_structures/mol_on_Rh(111).cif", mol_on_slab)
/home/jovyan/.py311/lib/python3.11/site-packages/ase/io/cif.py:836: UserWarning:
Occupancies present but no occupancy info for "{symbol}"
2-3 吸着E¶
Slabと分子それぞれが単体で存在していたときのエネルギーと、結合したときのエネルギー差を見ることで、吸着エネルギーが計算できます。
上記論文値では、1.79eVとなっています。値がずれているのは、論文ではRPBE汎関数が使われていますが、PFPではPBE汎関数が使われているところの違いが影響していそうです。
[21]:
# Calculate adsorption energy
adsorpE = slabE + molecE - mol_on_slabE
print(f"Adsorption Energy: {adsorpE} eV")
Adsorption Energy: 2.322510320482934 eV
2-4 吸着構造をリスト化¶
[22]:
ad_st_path = "output/ad_structures/*"
ad_stru_list = [(filepath, read(filepath)) for filepath in glob.glob(ad_st_path)]
[23]:
pd.DataFrame(ad_stru_list)
[23]:
| 0 | 1 | |
|---|---|---|
| 0 | output/ad_structures/mol_on_Rh(111).cif | (Atom('Rh', [1.0070710454703757, 1.00408247420... |
[24]:
No = 0
view_ngl(ad_stru_list[No][1] , representations=["ball+stick"])
[24]:
2-5 IS構造を作る¶
ここでIS構造・FS構造を自分で作成し、NEBを行うための経路を作ります。 今回はこちらで作成しているものを用いるので、 3. NEB計算 に飛んで頂いても構いません。
[25]:
filepath, atoms = ad_stru_list[No]
print(filepath)
IS = atoms.copy()
output/ad_structures/mol_on_Rh(111).cif
ここでは、FCCサイトに吸着している以下のような構造を作成してみましょう。
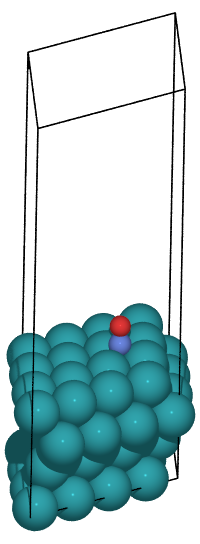
始状態: FCCサイトにNOが吸着している構造
[26]:
IS.calc = calculator
SurfaceEditor(IS).display()
[27]:
c = FixAtoms(indices=[atom.index for atom in IS if atom.position[2] <= 1])
IS.set_constraint(c)
BFGS_opt = BFGS(IS, logfile=None)
BFGS_opt.run(fmax=0.05)
IS.get_potential_energy()
[27]:
-383.5784274449586
2-6 FS構造を作る¶
同様に終状態を作成します。 本チュートリアルでは、N, Oそれぞれが移動し、HCPサイトに吸着した、以下のような構造を考えてみます。
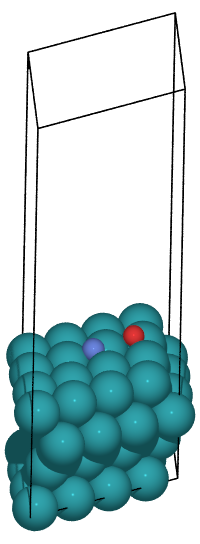
終状態: N, OそれぞれがHCPサイトに吸着している構造
[28]:
FS = IS.copy()
[29]:
FS.calc = calculator
SurfaceEditor(FS).display()
[30]:
FS.calc = calculator
c = FixAtoms(indices=[atom.index for atom in FS if atom.position[2] <= 1])
FS.set_constraint(c)
BFGS_opt = BFGS(FS, logfile=None)
BFGS_opt.run(fmax=0.005)
FS.get_potential_energy()
[30]:
-383.5784274449586
IS, FS構造を保存
[31]:
filepath = Path(filepath).stem
# filepath = Path(ad_stru_list[No][0]).stem
os.makedirs(filepath, exist_ok=True)
write(filepath+"/IS.cif", IS)
write(filepath+"/FS.cif", FS)
3. NEB計算¶
3-1 NEB計算¶
今回はこちらで作成した始状態・終状態ファイルを用いて、反応経路探索を行います。 matlantis-contrib/matlantis_contrib_examples/NEB_Solid_catalystでは、NO(fcc) -> N(fcc) + O(fcc) への反応に対するNEB計算を行っているので、 本Tutorialでは、NO(fcc) -> N(hcp) + O(hcp) の反応に対するNEB計算を試してみます。
[32]:
!cp -r "../input/NO_dissociation_NO(fcc)_N(fcc)_O(fcc)" .
!cp -r "../input/NO_dissociation_NO(fcc)_N(hcp)_O(hcp)" .
[33]:
# filepath = "NO_dissociation_NO(fcc)_N(fcc)_O(fcc)"
filepath = "NO_dissociation_NO(fcc)_N(hcp)_O(hcp)"
作成したIS, FS構造はこの様になっています。
[34]:
IS = read(filepath+"/IS.cif")
FS = read(filepath+"/FS.cif")
view_ngl([IS, FS], representations=["ball+stick"], replace_structure=True)
[34]:
[35]:
from pfcc_extras.visualize.povray import traj_to_gif
traj_to_gif(
[IS, FS],
gif_filepath=f"./output/{filepath}/NEB_IS_FS.gif",
pngdir=f"./output/{filepath}/png",
rotation="-60x, 30y, 15z",
clean=False,
)
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 2 out of 2 | elapsed: 1.1s finished
始状態: Initial State
終状態: Final State
[36]:
c = FixAtoms(indices=[atom.index for atom in IS if atom.position[2] <= 1])
IS.calc = calculator
IS.set_constraint(c)
BFGS_opt = BFGS(IS, logfile=None)
BFGS_opt.run(fmax=0.005)
print(f"IS {IS.get_potential_energy()} eV")
c = FixAtoms(indices=[atom.index for atom in FS if atom.position[2] <= 1])
FS.calc = calculator
FS.set_constraint(c)
BFGS_opt = BFGS(FS, logfile=None)
BFGS_opt.run(fmax=0.005)
print(f"FS {FS.get_potential_energy()} eV")
IS -383.1211239113131 eV
FS -383.93783990736733 eV
[37]:
beads = 21
NEBでparallel = True, allowed_shared_calculator=Falseにしたほうが、高速に処理が進みます。
[38]:
b0 = IS.copy()
b1 = FS.copy()
configs = [b0.copy() for i in range(beads-1)] + [b1.copy()]
for config in configs:
# Calculator must be set separately with NEB parallel=True, allowed_shared_calculator=False.
estimator = Estimator(calc_mode=EstimatorCalcMode.CRYSTAL_PLUS_D3, model_version="v8.0.0")
calculator = ASECalculator(estimator)
config.calc = calculator
まずはNEBを用いて反応経路候補となるconfigsの線形補間を行います。
[39]:
# k: spring constant. It was stable to when reduced to 0.05
neb = NEB(configs, k=0.05, parallel=True, climb=True, allow_shared_calculator=False)
neb.interpolate()
/tmp/ipykernel_4043/1063292405.py:2: FutureWarning:
Please import NEB from ase.mep, not ase.neb.
線形補間直後の反応経路候補を確認
[40]:
traj_to_gif(
configs,
gif_filepath=f"output/{filepath}/NEB_interpolate.gif",
rotation="-60x, 30y, 15z"
)
ImageWidget(f"output/{filepath}/NEB_interpolate.gif")
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 21 out of 21 | elapsed: 6.2s finished
[40]:
<IPython.core.display.Image object>
[41]:
view_ngl(configs, representations=["ball+stick"], replace_structure=True)
[41]:
ここから最適化を行います。
fmaxは0.05以下が推奨。小さすぎると収束に時間がかかります。 一回目のNEB計算は収束条件を緩め(0.2など)で実行し、無理のない反応経路が描けていたら収束条件を厳しくするほうが安定して計算できます。 緩めの収束条件で異常な反応経路となる場合はIS, FS構造を見直してください。
計算時間は十分程度かかるため、待つ必要があります。途中経過を確認したい時はneb_log.txtを参照しましょう。
[42]:
%%time
steps=2000
relax = FIRE(neb, trajectory=None, logfile=filepath+"/neb_log.txt")
# fmax<0.05 recommended. It takes time when it is smaller.
# 1st NEB calculation can be executed with loose condition (Ex. fmax=0.2),
# and check whether reaction path is reasonable or not.
# If it is reasonable, run 2nd NEB with tight fmax condition.
# If the reaction path is abnormal, check IS, FS structure.
relax.run(fmax=0.1, steps=steps)
CPU times: user 6.26 s, sys: 2.05 s, total: 8.31 s
Wall time: 14.1 s
[42]:
True
1回目の緩めの収束後、反応経路が異常でないかを確認。
[43]:
view_ngl(configs, representations=["ball+stick"], replace_structure=True)
[43]:
反応経路が問題ないことを確認後、収束条件をきつくして2回目収束を実行。
[44]:
# additional calculation
steps = 10000
relax.run(fmax=0.02, steps=steps)
[44]:
True
[45]:
write(filepath+"/NEB_images.xyz", configs)
4. NEB計算結果の確認と遷移状態構造取得¶
まずはいくつかの方法で可視化してみます。今回はpng –> gifファイルを作成してみます。
[46]:
configs = read(filepath+"/NEB_images.xyz", index=":")
[47]:
from pfcc_extras.visualize.povray import traj_to_gif
traj_to_gif(
configs,
gif_filepath=f"output/{filepath}/NEB_result.gif",
rotation="-60x, 30y, 15z"
)
ImageWidget(f"output/{filepath}/NEB_result.gif")
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 21 out of 21 | elapsed: 8.2s finished
[47]:
<IPython.core.display.Image object>
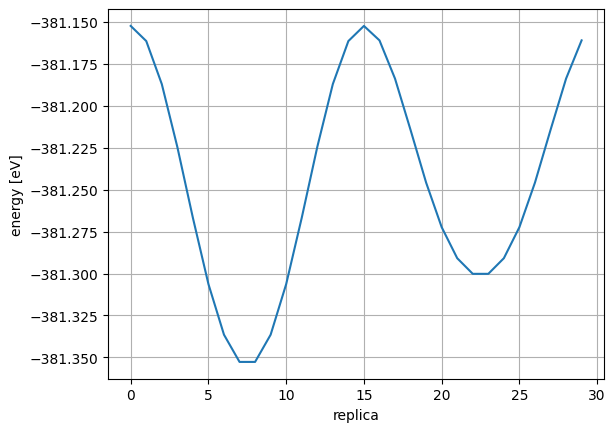
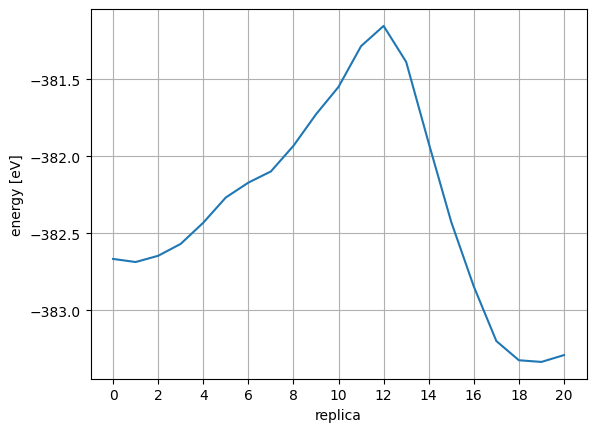
TS構造となったIndexを確認。 Energy, Forceをみてみると、index=12 で、エネルギーが最大、Forceが0付近の鞍点 (後述)に達している事がわかります。
[48]:
for config in configs:
config.calc = calculator
energies = [config.get_total_energy() for config in configs]
plt.plot(range(len(energies)),energies)
plt.xlabel("replica")
plt.ylabel("energy [eV]")
plt.xticks(np.arange(0, len(energies), 2))
plt.grid(True)
plt.show()
[49]:
def calc_max_force(atoms):
return ((atoms.get_forces() ** 2).sum(axis=1).max()) ** 0.5
mforces = [calc_max_force(config) for config in configs]
plt.plot(range(len(mforces)), mforces)
plt.xlabel("replica")
plt.ylabel("max force [eV]")
plt.xticks(np.arange(0, len(mforces), 2))
plt.grid(True)
plt.show()
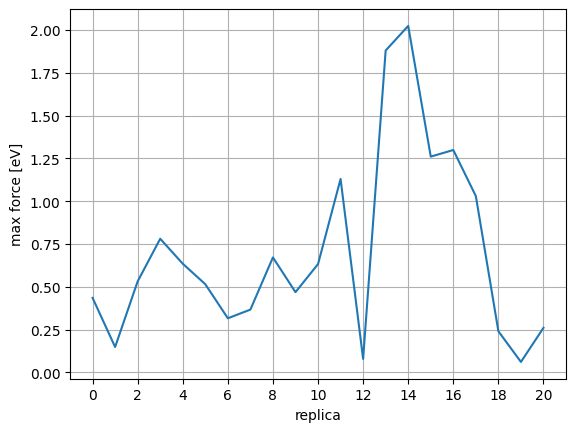
max forceのPlotで確認すべきことは以下の3点で、forceが0に近い値になっていることです。
始状態 (index=0)
遷移状態 (index=12)
終状態 (index=20)
ただし、今回のようにFixAtomsを行って固定している原子がある場合、その部分のForceが大きいと0にはならないことがあります。
初期構造 index=0 と、遷移状態 index=12のエネルギー差を見ることで活性化エネルギーが計算できます。
[50]:
ts_index = 12
actE = energies[ts_index] - energies[0]
deltaE = energies[ts_index] - energies[-1]
print(f"actE {actE} eV, deltaE {deltaE} eV")
actE 1.2681674393558637 eV, deltaE 2.0849356133056745 eV
NEBやり直し¶
実行済みのNEB計算結果から中間イメージのほうが始状態、終状態に適した構造が出た場合に、その構造を抽出して再実行してください。
5. 遷移状態構造の構造最適化(by Sella)¶
上記のNEBで得られたTS構造は、厳密な鞍点まで収束させる操作が入っていません。(※) ここでは、sella というライブラリを用いて、TS構造を収束させます。
※鞍点とは:
始状態や終状態は局所的に最小値を取っている構造です。つまり微小変位したときにすべての方向でエネルギーが上がるため、4章のVibraionでも説明したとおりHessianを対角化した際にすべての成分が正となります(2次微分が正定値行列で、直感的にはどの方向に対しても\(y=ax^2 (a>0)\)のような関数系になっているということです)。
それに対して遷移状態というのは、Hessianの対角成分の1つだけが負となり、残りの成分が正となります。 つまり、1つの始状態と終状態を結ぶ方向に対してのみエネルギーが下がり(局所的に\(y=ax^2 (a<0)\)のような形状)、 その他の方向に向かうとエネルギーが高くなるような点です。このような点を鞍点と呼びます。
前節で用いた以下の図もご参照ください。
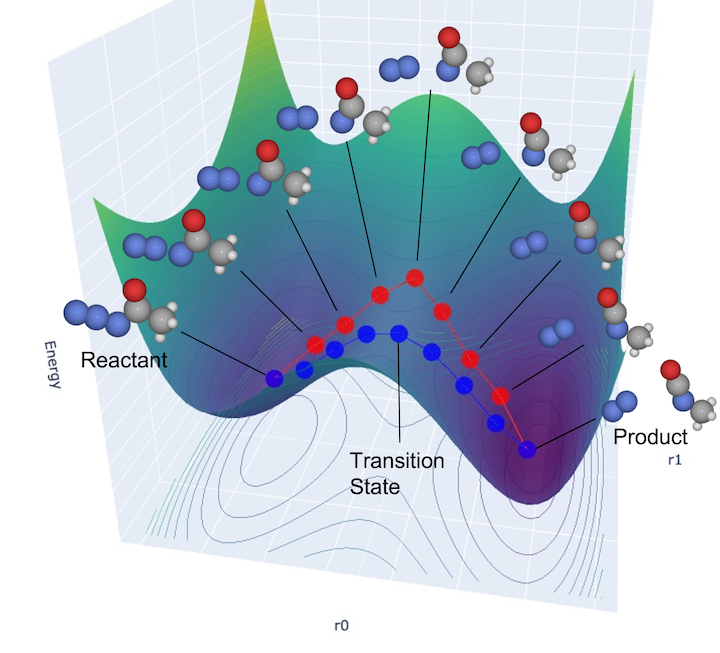
厳密な活性化エネルギーを求めるためには、厳密な遷移状態の点を求める事が必要です。
[51]:
!pip install sella
Looking in indexes: https://pypi.org/simple, http://pypi.artifact.svc:8080/simple
Requirement already satisfied: sella in /home/jovyan/.py311/lib/python3.11/site-packages (2.3.5)
Requirement already satisfied: numpy>=1.14.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from sella) (1.26.4)
Requirement already satisfied: scipy>=1.1.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from sella) (1.15.3)
Requirement already satisfied: ase>=3.18.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from sella) (3.25.0)
Requirement already satisfied: jax>=0.4.20 in /home/jovyan/.py311/lib/python3.11/site-packages (from sella) (0.6.2)
Requirement already satisfied: jaxlib>=0.4.20 in /home/jovyan/.py311/lib/python3.11/site-packages (from sella) (0.6.2)
Requirement already satisfied: matplotlib>=3.3.4 in /home/jovyan/.py311/lib/python3.11/site-packages (from ase>=3.18.0->sella) (3.10.3)
Requirement already satisfied: ml_dtypes>=0.5.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from jax>=0.4.20->sella) (0.5.1)
Requirement already satisfied: opt_einsum in /home/jovyan/.py311/lib/python3.11/site-packages (from jax>=0.4.20->sella) (3.4.0)
Requirement already satisfied: contourpy>=1.0.1 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (1.3.2)
Requirement already satisfied: cycler>=0.10 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (4.58.2)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (1.4.8)
Requirement already satisfied: packaging>=20.0 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (25.0)
Requirement already satisfied: pillow>=8 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (11.2.1)
Requirement already satisfied: pyparsing>=2.3.1 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (3.2.3)
Requirement already satisfied: python-dateutil>=2.7 in /home/jovyan/.py311/lib/python3.11/site-packages (from matplotlib>=3.3.4->ase>=3.18.0->sella) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/jovyan/.py311/lib/python3.11/site-packages (from python-dateutil>=2.7->matplotlib>=3.3.4->ase>=3.18.0->sella) (1.17.0)
[notice] A new release of pip is available: 24.0 -> 25.1.1
[notice] To update, run: pip install --upgrade pip
[52]:
TSNo = 12
TS = configs[TSNo].copy()
c = FixAtoms(indices=[atom.index for atom in TS if atom.position[2] <= 1])
TS.set_constraint(c)
[53]:
from sella import Sella, Constraints
TS.calc = calculator
# TS optimization with Sella
TSopt = Sella(TS)
%time TSopt.run(fmax=0.05)
potentialenergy = TS.get_potential_energy()
print (TS.get_potential_energy(), TS.get_forces().max())
Step Time Energy fmax cmax rtrust rho
Sella 0 05:16:31 -381.852938 0.0007 0.0000 0.1000 1.0000
CPU times: user 53.5 ms, sys: 7.4 ms, total: 60.9 ms
Wall time: 162 ms
-381.85293756860995 0.0003595982361730421
[54]:
write(filepath + "/TS_opt.cif", TS)
[55]:
# Compare before and after TS optimization
view_ngl([configs[TSNo], TS], representations=["ball+stick"], replace_structure=True)
[55]:
6. 遷移状態の振動解析¶
遷移状態は、2次微分が1つだけのみ負になっており、ほかは正である鞍点である必要があります。 もし、2つ以上負になるような場合は、その点よりも低い位置により活性化エネルギーの低い遷移状態があることが示唆されます。
きちんと遷移状態が求められているかを確認するために、振動解析を行ってみます。
[56]:
# Vibration analysis is executed with atoms `z_pos >= zz`
z_pos = pd.DataFrame({
"z": TS.positions[:, 2],
"symbol": TS.symbols,
})
vibatoms = z_pos[z_pos["z"] >= 7.0].index
vibatoms
[56]:
Index([64, 65], dtype='int64')
[57]:
# Vibration analysis
vibpath = filepath + "/TS_vib/vib"
os.makedirs(vibpath, exist_ok=True)
# Vibration analysis is executed with only specified atoms `indices=vibatoms`
vib = Vibrations(TS, name=vibpath, indices=vibatoms)
vib.run()
vib_energies = vib.get_energies()
thermo = IdealGasThermo(vib_energies=vib_energies,
potentialenergy=potentialenergy,
atoms=TS,
geometry='linear', #'monatomic', 'linear', or 'nonlinear'
symmetrynumber=2, spin=0, natoms=len(vibatoms),
ignore_imag_modes=True)
G = thermo.get_gibbs_energy(temperature=298.15, pressure=101325.)
Enthalpy components at T = 298.15 K:
===============================
E_pot -381.853 eV
E_ZPE 0.034 eV
Cv_trans (0->T) 0.039 eV
Cv_rot (0->T) 0.026 eV
Cv_vib (0->T) 0.005 eV
(C_v -> C_p) 0.026 eV
-------------------------------
H -381.724 eV
===============================
Entropy components at T = 298.15 K and P = 101325.0 Pa:
=================================================
S T*S
S_trans (1 bar) 0.0022653 eV/K 0.675 eV
S_rot 0.0012595 eV/K 0.376 eV
S_elec 0.0000000 eV/K 0.000 eV
S_vib 0.0000236 eV/K 0.007 eV
S (1 bar -> P) -0.0000011 eV/K -0.000 eV
-------------------------------------------------
S 0.0035474 eV/K 1.058 eV
=================================================
Free energy components at T = 298.15 K and P = 101325.0 Pa:
=======================
H -381.724 eV
-T*S -1.058 eV
-----------------------
G -382.781 eV
=======================
[58]:
vib.summary()
---------------------
# meV cm^-1
---------------------
0 63.1i 509.1i
1 20.0 161.2
2 36.6 295.1
3 51.7 417.1
4 61.0 491.8
5 68.2 549.7
---------------------
Zero-point energy: 0.119 eV
きちんと 1つのみ負の振動数 (虚数の波数) が得られていることが確認できました。
[59]:
vib.summary(log=filepath+"/vib_summary.txt")
各振動モードの表示用のtrajファイルを出力します。
[60]:
vib.write_mode(n=0, kT=300*kB, nimages=30)
vib.clean()
[60]:
13
summary tableを見ながら表示したい振動モードの番号を入力してください。
[61]:
n = 0
vib_traj = Trajectory(vibpath + f".{n}.traj")
view_ngl(vib_traj, representations=["ball+stick"])
[61]:
[62]:
write(filepath + "/vib_traj.xyz", vib_traj)
[63]:
vib_traj = read(filepath + "/vib_traj.xyz", index=":")
[64]:
from pfcc_extras.visualize.povray import traj_to_gif
traj_to_gif(
vib_traj,
gif_filepath=f"output/{filepath}/vib.gif",
rotation="-60x, 30y, 15z"
)
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 30 out of 30 | elapsed: 10.8s finished
[65]:
ImageWidget(f"output/{filepath}/vib.gif")
[65]:
<IPython.core.display.Image object>
虚振動になっているか確認する。真ん中(と0)がTS。
[66]:
vib_energies = []
for i in vib_traj:
i.calc = calculator
vib_energies.append(i.get_potential_energy())
plt.plot(range(len(vib_energies)), vib_energies)
plt.xlabel("replica")
plt.ylabel("energy [eV]")
plt.grid(True)
plt.show()